한도를 높이면 부도가 늘어날까? 공개 데이터 3종으로 검증한 기록
신용 한도를 올리면 그 사람의 부도 확률은 올라갈까요, 내려갈까요. 상식적으로는 올라갈 것 같지만, 데이터는 정반대로 '내려간다'고 답합니다. 이 역설을 디바이어싱으로 풀고, 공개 데이터 세 가지로 검증하면서, 한도 효과의 부호가 언제 뒤집히는지를 정리했습니다.
신용카드 한도를 올려주면 그 사람이 부도날 확률은 올라갈까요, 내려갈까요. 상식적으로는 올라갈 것 같습니다. 더 많이 빌릴 수 있으니까요. 그런데 데이터를 열어보면 정반대입니다. 이 글은 그 역설을 디바이어싱(debiasing)으로 풀고, 공개 데이터 세 가지로 검증하면서, 마지막에 의외의 결론에 닿는 기록입니다.
Part 0에서 선택편향 이야기를 했습니다. 이번 글은 그 선택편향이 인과추론과 정면으로 만나는 실전 사례입니다. 인과추론 자체는 기초 연재에서 따로 깊게 다루지만, 여기서는 그것이 실무에서 어떻게 작동하는지 한발 먼저 보여드립니다. 코드와 데이터는 모두 공개된 것만 썼습니다.
1. 직관과 정반대인 데이터
먼저 대만 신용카드 데이터로 시작합니다. 2005년 대만의 카드 고객 3만 명에 대해, 각자의 한도와 청구액(잔액), 그리고 다음 달에 연체했는지를 담은 공개 데이터입니다(UCI 공개). 한도, 잔액, 부도를 한꺼번에 가진 드문 공개 데이터라 출발점으로 좋습니다. 여기서 한도 구간별 실제 부도율을 그려봅니다.
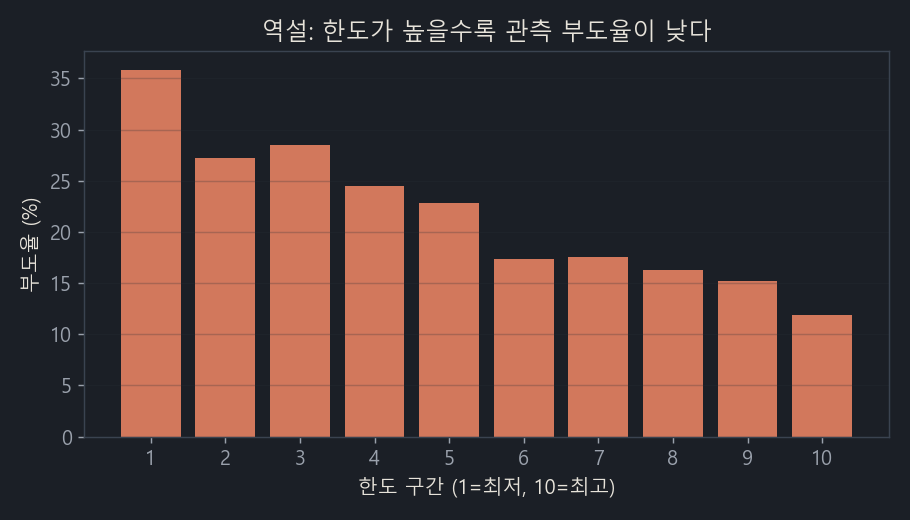
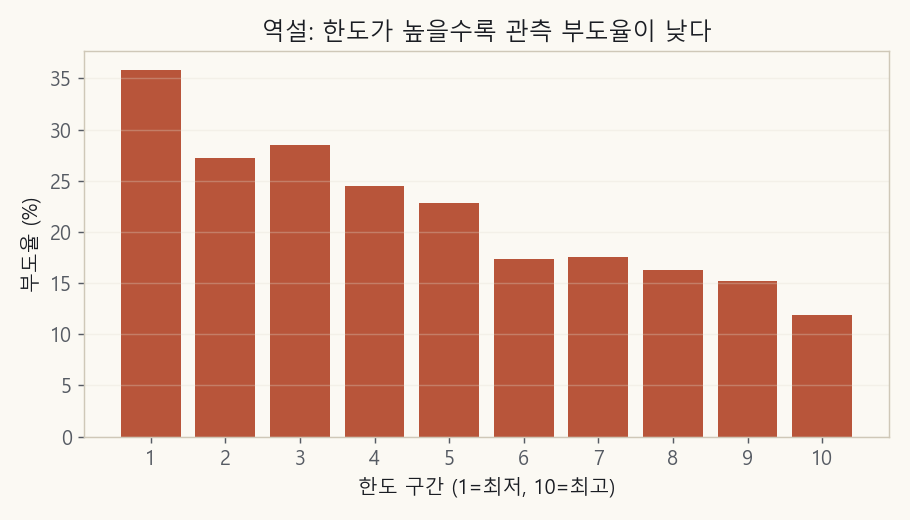
한도 최하위 10%의 부도율은 35.9%, 최상위 10%는 11.9%입니다. 한도가 높을수록 부도율이 꾸준히 낮아집니다(상관계수 −0.15).
한도를 20배 가까이 높게 받은 집단이 부도는 3분의 1 수준으로만 냅니다. 한도를 막 늘려줘도 된다는 뜻일까요? 당연히 아닙니다. 여기엔 함정이 있습니다.
2. 범인은 선택 편향
한도는 무작위로 주어지지 않습니다. 기존의 모델이나 룰에 따라, 애초에 신용이 좋은 사람에게 높은 한도가 부여됩니다. 그래서 “한도가 높다”는 것은 곧 “원래 잘 갚을 사람”이라는 신호입니다. 한도와 부도의 음(−)의 관계는 한도의 효과가 아니라, 한도 뒤에 숨은 신용도가 만든 허상입니다. Part 0에서 본 선택편향이 가장 노골적으로 작동하는 사례입니다.
데이터를 그대로 학습시키면 모델은 “한도 높음 = 안전”이라고 배웁니다. 이 모델로 “한도를 올리면?”을 시뮬레이션하면 부도가 줄어든다고 답합니다. 이 결과를 정책 판단에 그대로 쓰면 위험합니다.
3. 해법: 한도를 “잔차”로 바꾸기
핵심 아이디어는 단순합니다. 신용도가 똑같은데 한도만 다른 사람들을 비교하면 한도의 순수 효과가 보입니다. 완벽한 매칭은 불가능하니 대신 이렇게 합니다.
- 신용도 피처(X)로 각자의 ‘예상 한도’를 예측합니다(기존 한도 부여 방식의 모방).
- 실제 한도에서 예상 한도를 뺀 값이 한도 잔차(rL)입니다. 신용도로 설명되지 않는, 정책이나 우연이 만든 한도의 변동분입니다.
- 잔액과 부도도 같은 방식으로 잔차로 만듭니다.
- 한도 잔차에서 잔액 잔차로, 다시 부도로 이어지는 체인을 세웁니다(한도→잔액→부도 경로).
- 부도는 0과 1이라 로짓 공간에서 차이를 보정하고, 처음 예측한 부도확률에 그 보정을 더해 최종값을 만듭니다.
주의 두 가지가 있습니다. 첫째, 데이터 누수를 막기 위해 잔차는 반드시 교차적합(cross-fitting)으로 만들어야 합니다. 자기 자신을 보고 예측하면 잔차가 가짜로 작아집니다. 둘째, 한도 부여가 일관될수록 잔차가 큰 사람이 드뭅니다. 그 드문 “자연실험” 표본(잔차가 큰 사람)에 가중치를 더 줍니다.
이건 인과추론의 Double Machine Learning(DML)과 같은 구조입니다. DML은 이렇게 요약됩니다. 처치(여기선 한도)와 결과(부도)를 각각 머신러닝으로 교란변수(신용도)에서 예측해 빼낸 뒤, 남은 잔차끼리의 관계로 효과를 추정합니다. 머신러닝이 교란을 유연하게 흡수하되, 그 모델의 편향이 효과 추정으로 새지 않도록 교차적합으로 분리하는 것이 핵심입니다. 결국 한도라는 처치에서 신용도라는 교란을 걷어내는 일입니다.
시작하기 전, 한 가지 한계를 미리 짚겠습니다. 우리가 통제하는 신용도 피처는 진짜 한도 부여 기준(소득, 외부 신용점수 등)의 대리변수일 뿐입니다. 그래서 디바이어싱은 편향을 “줄이는” 것이지 “완전히 없애는” 것이 아닙니다. 통제 변수가 부실한 데이터일수록, 제거 후에 남은 음(−)에는 못 걷어낸 편향이 섞여 있을 수 있습니다.
4. 검증 1, 대만 신용카드: 편향은 사라졌지만 효과도 거의 사라졌다
디바이어싱을 적용하자 역설이 풀렸습니다. 한도와 부도의 겉보기 상관 −0.15 가운데 약 70%가 선택 편향이었고, 제거하고 남은 직접 효과는 작은 음(−0.05)이었습니다. 가설(“한도↑→부도↑“)과는 반대 방향입니다.
그럼 가설은 어디서 검증할까요. 반사실(counterfactual), 전원의 한도를 0.5배에서 2배로 바꿔보며 예측 부도율을 그린 그림입니다.
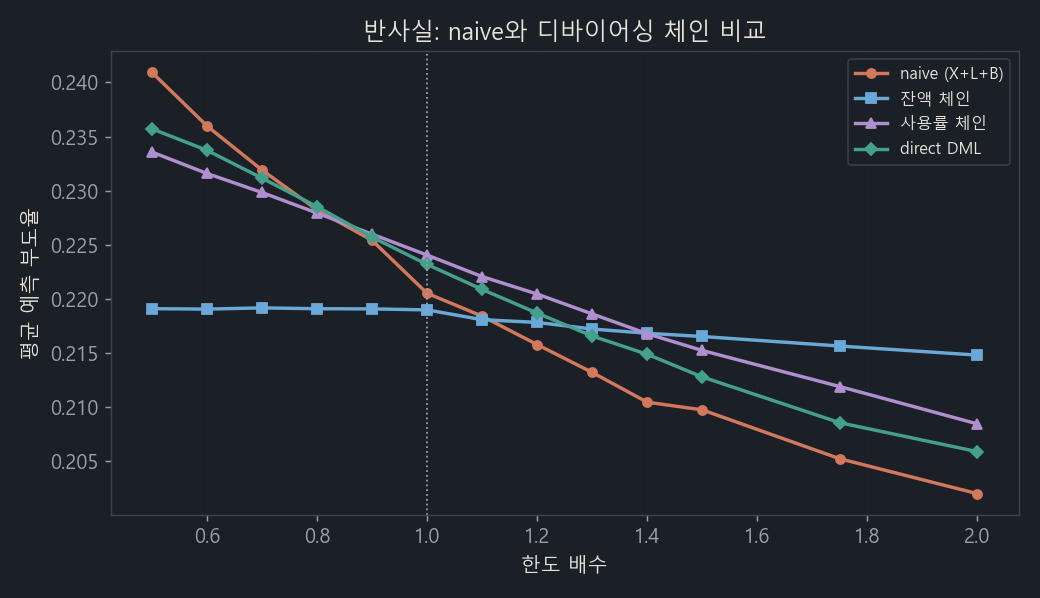
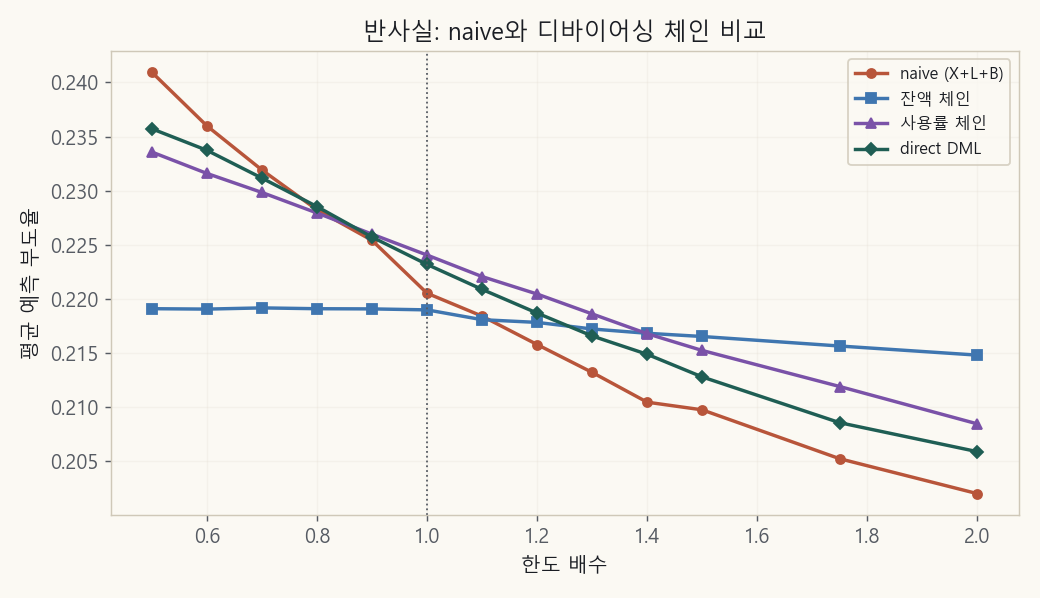
빨강(naive)은 한도↑→부도↓라는 역설을 그대로 출력합니다. 잔액 체인(파랑)은 거의 평탄해집니다. 사용률과 직접(direct) 체인(보라, 초록)은 약한 음을 유지합니다.
자세히 분석해 보면 다음과 같은 점을 알 수 있습니다.
- 한도→잔액은 양(+)이지만 전이율이 5.7%로 약합니다. 한도를 1만큼 늘려도 잔액은 0.057만큼만 늘어난다는 뜻입니다. 전액 인출되는 할부대출이면 이 값이 100%에 가까운데, 그에 비하면 리볼빙 한도는 거의 안 쓰여서 부담으로 잘 전환되지 않습니다(sticky).
- 진짜 부담 신호는 잔액이 아니라 사용률(잔액/한도)이었습니다. 그리고 한도를 늘리면 사용률은 오히려 크게 떨어집니다(−0.39, 여유가 생김).
- 잔액만 떼어 선형으로 깨끗이 추정하면 잔액→부도는 유의한 양(+)(p=0.001)이라 가설이 성립합니다. 다만 크기가 극히 작습니다.
여기서 방법론에 대한 교훈이 하나 나옵니다. 신호가 약한 잔차 단계에 유연한 GBM을 쓰면 과적합합니다. train AUC는 올라가는데 test AUC는 오히려 기본 모델보다 떨어졌고, train과 test의 격차가 0.047로 기본 모델의 0.008보다 여섯 배 벌어졌습니다. 반면 잔차만 쓰는 선형 2차 스테이지는 격차가 0.009로 거의 없고, 진짜 효과를 깨끗이 복원했습니다. 약한 인과 신호는 선형이나 규제 모델로 다루는 것이 적절할 수 있습니다.
5. 함정 하나: 관측창이 너무 짧다
이 데이터의 부도는 “다음 1개월” 연체입니다. 실무의 대손 모델은 보통 12개월 뒤를 봅니다. 짧은 창에는 분석에 큰 영향을 주는 편향이 하나 더 있습니다. 연명(postponement)입니다. 한도 여유가 있는 사람은 그 여유로 한 달 더 버텨서 부도가 관측창 밖으로 밀려납니다. 부도가 줄어든 게 아니라 미뤄진 것뿐인데 “안전함”으로 기록됩니다.
이건 디바이어싱(교란 제거)으로는 못 잡는 별개의 편향(생존, 검열)입니다. 관측창을 1개월에서 5개월로 늘려가며 확인했습니다.
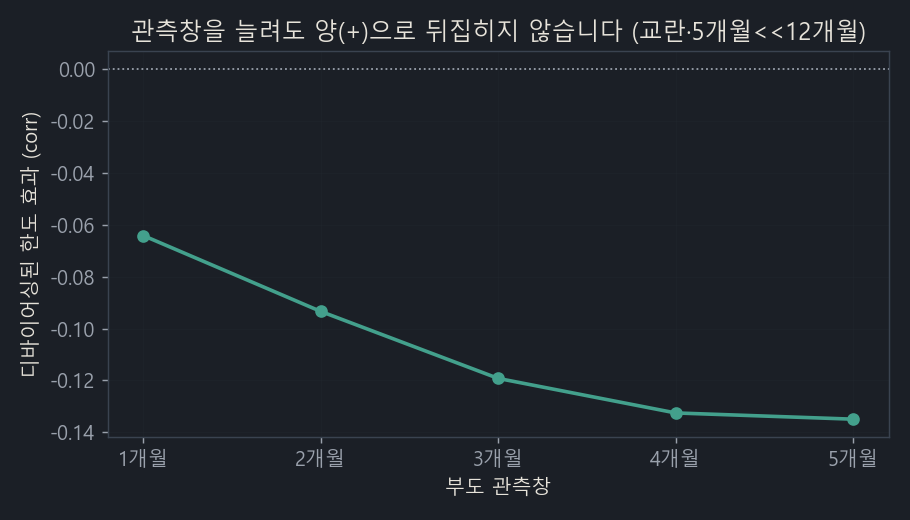
창을 늘려도 음(−)이 양(+)으로 뒤집히지는 않았습니다(1개월 −0.06에서 5개월 −0.13). 다만 이 실험은 창을 늘릴수록 신용도 통제가 얇아져 교란되고, 5개월은 12개월에 한참 못 미칩니다. 즉 UCI(1개월)로는 12개월 문제를 검증할 수 없다는 결론입니다.
그래서 진짜 장기 데이터가 필요했습니다.
6. 검증 2, Lending Club: 장기 그리고 ‘인출된’ 여신
Lending Club은 미국의 P2P 대출 플랫폼입니다. 2007년에서 2013년 사이에 나가 이미 만기가 끝난 대출 23만 건을 씁니다. 만기가 끝났으니 완납인지 상각(charge-off)인지 최종 결과를 알 수 있습니다. 여기에 같은 디바이어싱을 돌리자, 결정적인 구분이 드러납니다.
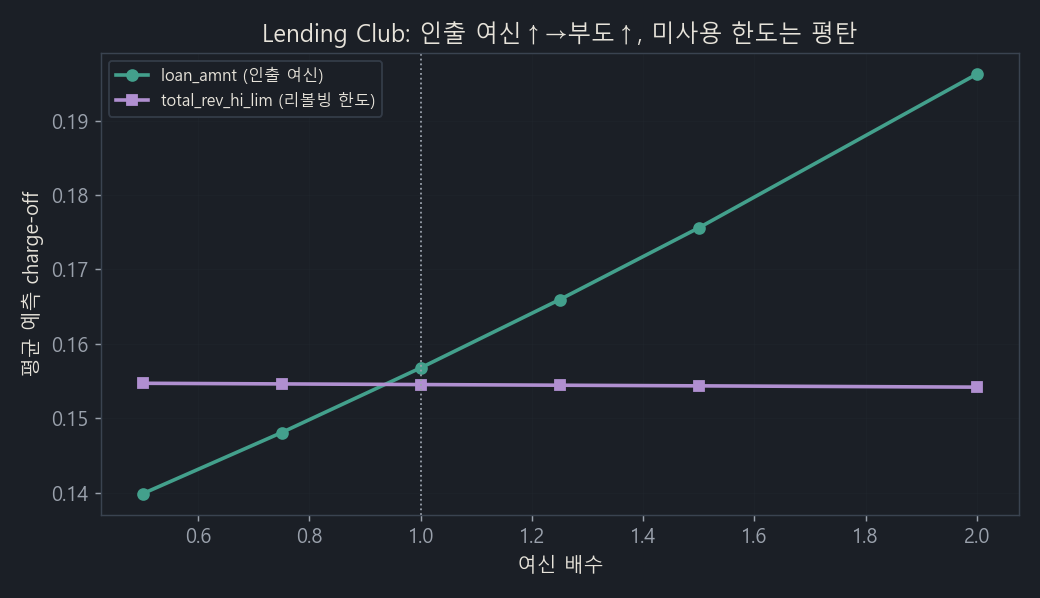

loan_amnt(인출된 여신, 초록): 디바이어싱 후에도 여신↑→부도↑가 깨끗하게 성립합니다(p<0.0001). 여러 위험등급에서 일관되게 증가하고, 오히려 편향 제거가 효과를 더 강화했습니다. 가설 성립입니다.total_rev_hi_lim(미사용 리볼빙 한도, 보라): 장기에서도 효과가 거의 0입니다. UCI의 한도와 똑같습니다.
차이의 본질은 관측창이 아니라 “인출된 여신이냐, 미사용 한도냐”였습니다. 할부대출은 전액 인출되어 100% 부담이 되지만, 리볼빙 한도는 끌어 쓰기 전엔 부담이 아닙니다(headroom). 둘을 잇는 다리가 전이율(한도→잔액)이고, UCI에서 그게 5.7%에 불과했기에 한도 효과가 약했던 것입니다.
7. 검증 3, Home Credit 카드: 대손 정의가 부호를 뒤집다
Home Credit은 Kaggle 대회로 공개된 데이터로, 신용카드 월별 패널과 신청 대출(할부) 두 종류를 담고 있습니다. 먼저 카드 패널, 즉 같은 리볼빙 상품에서 실제 한도와 잔액, 연체를 수십 개월 추적한 데이터로 못을 박으려 했습니다. 그런데 결과가 또 뒤집혔습니다. 이번엔 경고였습니다.
실제로 쓰이는 활성 카드 약 1.6만 개를 보니, 사용률이 높을수록 부도가 낮게 나오는, UCI와 정반대 방향이 나왔습니다. 왜일까요.
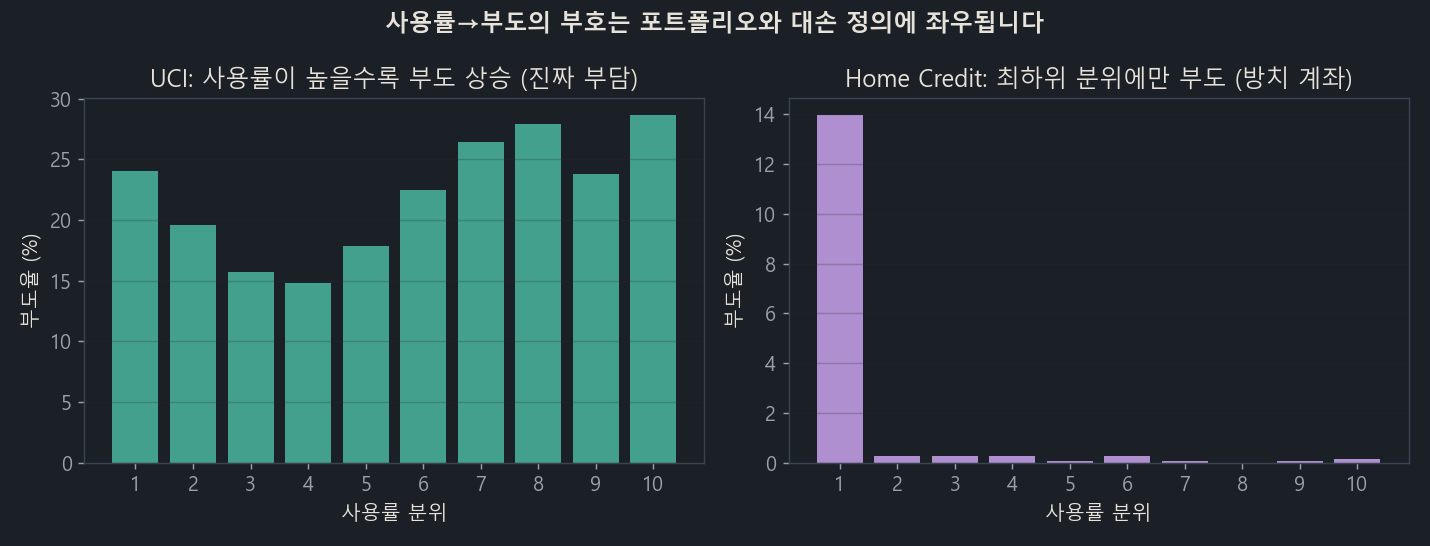
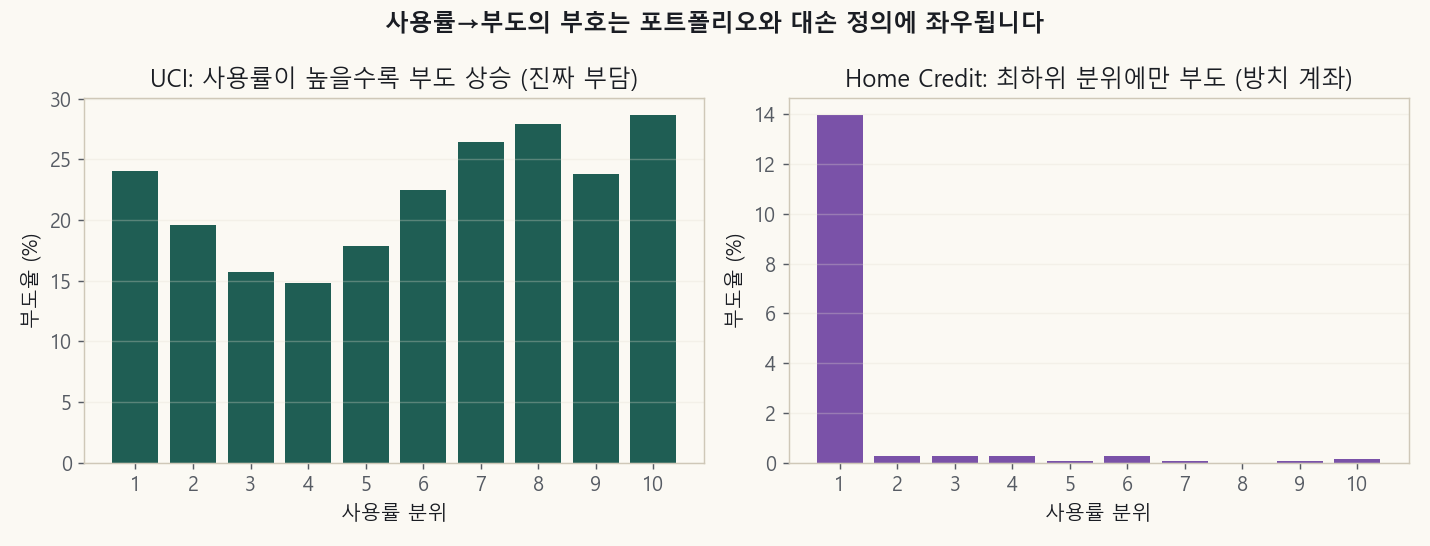
왼쪽 UCI는 사용률이 높을수록 부도율이 오릅니다(진짜 부담). 오른쪽 Home Credit은 최하위 사용률 분위(잔액이 거의 0)에만 부도가 약 14%로 몰려 있고, 나머지 분위는 0.1% 안팎입니다.
원인은 명확했습니다. Home Credit의 “부도(SK_DPD≥90)“는 신용 부담이 아니라 소액 잔액을 방치해 연체된 휴면계좌를 잡고 있었습니다. 카드를 실제로 쓰는 사람은 부도가 사실상 0입니다. 즉 부도(outcome) 정의가 ‘신용손실’이 아니라 ‘방치’를 잡으면, 아무리 디바이어싱을 잘해도 부호가 통째로 뒤집힙니다.
8. 검증 4, Home Credit 본 대출: 드디어 역설이 뒤집히다
지금까지 디바이어싱을 시도했지만, raw에서 음(−)이던 역설이 디바이어싱 후 양(+)으로 뒤집히는 데이터는 없었습니다. 그 조건을 갖춘 데이터도 그 옆에 있었습니다. 같은 Home Credit의 신청 대출(카드가 아니라 본 대출, 부도율 8%, 30만 건)입니다. 전액 인출되는 할부대출이고, 부도는 진짜 신용손실입니다. 그리고 이번엔 외부 신용점수(EXT_SOURCE)와 소득을 함께 통제했습니다.
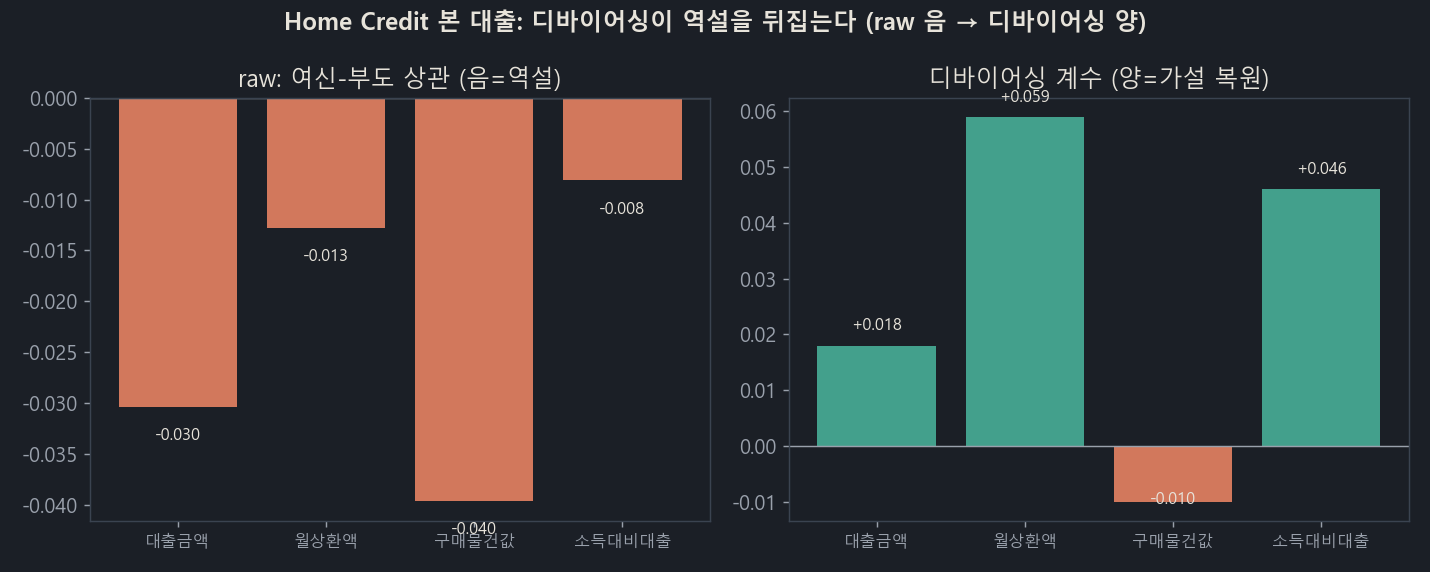
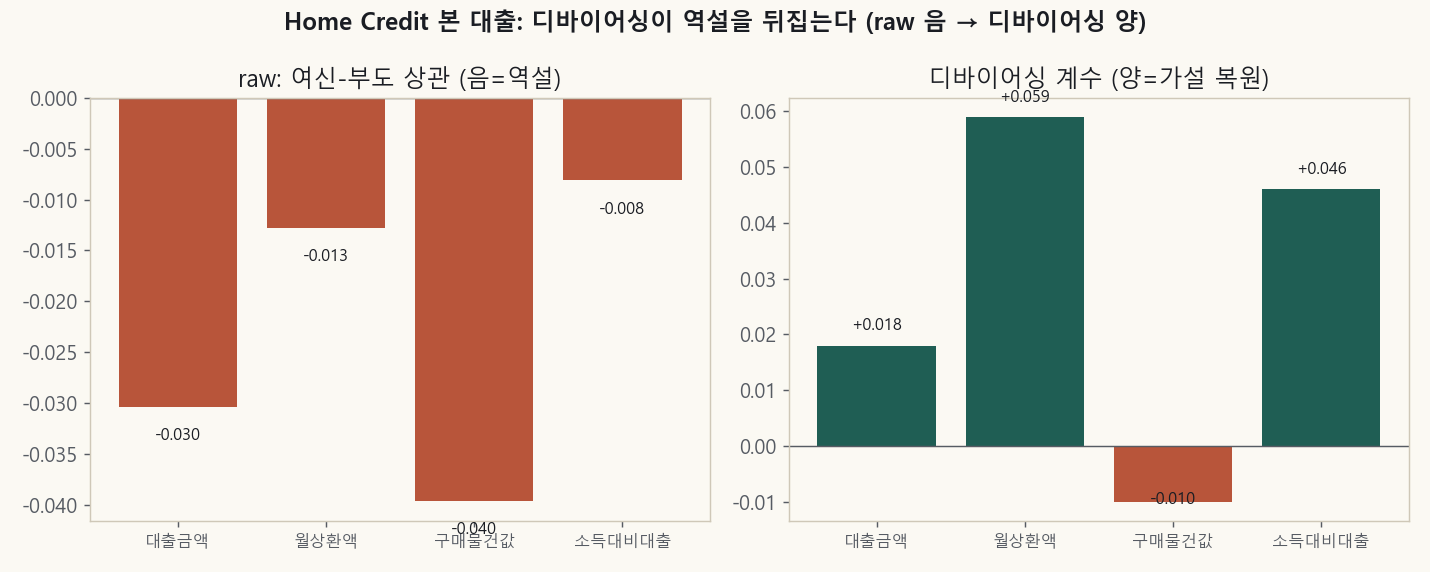
왼쪽(raw)은 여신이 클수록 부도가 낮은 역설(네 변수 모두 음)입니다. 오른쪽(디바이어싱)은 신용도를 제거하니 양(+)으로 뒤집힙니다.
| 변수 | raw 상관 | 디바이어싱 계수 | 판정 |
|---|---|---|---|
| 대출금액 | −0.030 | +0.018 | 뒤집힘 |
| 월상환액 | −0.013 | +0.059 (p≈10⁻²⁰) | 뒤집힘 (최강) |
| 소득 대비 대출 | −0.008 | +0.046 | 뒤집힘 |
| 구매 물건값 | −0.040 | −0.010 | 안 뒤집힘 |
표의 계수는 표준화한 잔차에 대한 로짓 계수라, 크기 자체는 작습니다. 월상환액 +0.059는 1 표준편차 늘 때 부도 오즈가 약 6% 오른다는 정도입니다. 30만 건이라 p값이 극도로 작은데, 이건 “효과가 크다”가 아니라 “부호가 양(+)이라는 게 확실하다”는 뜻입니다. 이 글의 주장은 크기가 아니라 방향(음에서 양으로 뒤집힘)에 있습니다.
흥미롭게도 구매 물건값(AMT_GOODS_PRICE)만 안 뒤집힙니다. 갚아야 할 부담은 대출금과 상환액이지 물건값 자체가 아니니, 이론과 정확히 맞습니다.
그렇다면 왜 여기선 뒤집히고 UCI나 Lending Club 리볼빙 한도에선 안 뒤집혔을까요. 두 조건이 동시에 맞아야 합니다. 첫째, 인출된 여신(전액 빌려 쓴 실부담)이라 진짜 효과가 양(+)일 것. 둘째, 선택편향이 강해서(큰 대출일수록 우량고객) raw가 음(−)일 것. 본 대출은 둘 다 충족합니다. 그래서 raw는 선택편향에 가려 음이고, 디바이어싱하면 진짜 부담 효과인 양이 드러납니다.
9. 종합: 역설은 언제 뒤집히는가
| 신용의 종류 | raw 한도-부도 | 디바이어싱 후 | 사례 |
|---|---|---|---|
| 미사용 리볼빙 한도 | 음 (역설) | 거의 0 | UCI, LC, HC 카드 |
| 인출 여신, 약한 선택 | 양 (역설 없음) | 양 | LC 대출금 |
| 인출 여신, 강한 선택 | 음 (역설) | 양 (뒤집힘) | HC 본 대출 |
세 데이터를 관통하면 두 가지가 남습니다.
- “한도↑→부도↑“는 보편 법칙이 아닙니다. 미사용 한도는 안 쓰면 부담이 아니라 효과가 거의 0이고, 사용률과 잔액의 부호는 포트폴리오와 대손 정의에 좌우됩니다.
- 그러나 역설은 조건이 맞으면 실제로 뒤집힙니다. 디바이어싱은 가짜 음(−)을 걷어내고 진짜 양(+)을 복원합니다. 단, 그럴 수 있는 신용(인출된 실부담)에 한해서입니다.
10. 그래서 실무에서는
이 결과를 실무로 가져갈 때 두 가지를 먼저 강조하고 싶습니다.
하나는 한계입니다. 디바이어싱이 통제하는 신용도 피처는 진짜 한도 부여 기준의 대리변수일 뿐이라, 남은 효과를 “순수 인과”로 단정하면 안 됩니다. 특히 소득이나 외부 점수가 없어 실제 신용도를 재현하기 어려운 데이터일수록 그렇습니다. 또 이 글은 부도확률(PD)을 다뤘지만, 실무의 대손율은 손실 금액 기반일 때가 많습니다. 손실 금액은 한도와 기계적으로 연동되므로(한도↑→익스포저↑→손실 금액↑), 같은 데이터라도 부호가 양(+)으로 보일 수 있습니다. 무엇을 outcome으로 두느냐가 결론을 바꿉니다.
그래서 방법과 결론을 분리해야 합니다.
- 방법(디바이어싱)은 타당하고 이식 가능합니다. 진짜 양(+)의 효과가 있을 때(Lending Club 인출 여신) 방법은 그것을 깨끗이 복원했습니다. 다른 데이터에서 음(−)이 나온 건 방법의 실패가 아니라 “그 신용은 원래 부도를 안 올린다”는 사실의 정확한 반영입니다.
- 방향성 결론은 이식 불가능합니다. 공개 데이터로 “어느 포트폴리오에서나 한도↑→부도↑“라고 단정할 수 없습니다.
- 실무 데이터에서 반드시 확인할 두 가지가 있습니다. 첫째는 전이율(dBalance/dLimit), 한도 증액이 실제 인출 부담으로 얼마나 전환되는가입니다. 둘째는 대손 정의, 12개월 대손이 진짜 신용손실을 잡는가 아니면 방치나 소액연체를 잡는가입니다.
이 두 가지가 한도 효과의 부호를 결정합니다. 디바이어싱은 출발점일 뿐, 정답은 각자의 포트폴리오에 있습니다.
부록. 데이터와 재현
- UCI “Default of Credit Card Clients” (대만, 3만 건, 1개월 연체)
- Lending Club 2007년에서 2013년 만기 완료 대출 (23만 건, charge-off)
- Home Credit
credit_card_balance카드 패널과application_train본 대출 (30만 건, 부도 8%) - 방법: K-fold 교차적합 잔차화, isotonic 캘리브레이션, 잔차 가중, 선형 2차 스테이지(DML). Python(pandas, scikit-learn, lightgbm, statsmodels).
- 코드와 노트북(한국어·일본어): github.com/HangilKim11/blog-research
이 글의 수치와 그림은 모두 공개 데이터로 재현할 수 있습니다. 본문의 결론은 공개 데이터에 대한 것이며, 실무 데이터의 부호는 위 두 가지로 직접 확인해야 합니다.